Difference Between Supervised and Unsupervised Learning
Are you curious about the exciting world of machine learning? As technology continues to advance at a rapid pace, machine learning has become a vital tool for businesses and organizations looking to extract insights from their data. In this article, we'll dive into the differences between two major approaches in machine learning: supervised and unsupervised learning. As a data scientist, I have found these techniques to be essential for solving real-world problems, and I'm excited to share my insights with you. So buckle up and get ready to explore the fascinating world of machine learning with me, Ankit.

Introduction
Machine learning is the process of training machines to make decisions and predictions based on data. In this process, the machine is given a dataset that it can learn from and make predictions based on that learning. Supervised and unsupervised learning are two major approaches in machine learning, and they differ in the way they use data to train a machine.
Supervised Learning
Supervised learning is a type of machine learning in which the machine is trained on a labeled dataset. This means that the dataset has input variables (also known as features) and output variables (also known as labels). The machine is given the input variables along with the corresponding output variables, and it uses this information to learn a mapping function from input variables to output variables.
In supervised learning, the machine is given a specific task to perform, and it uses the labeled dataset to learn how to perform that task. This type of learning is commonly used in tasks such as image classification, speech recognition, and sentiment analysis.

Example of Supervised Learning
An example of supervised learning is predicting house prices based on features such as square footage, number of bedrooms, and location. In this case, the input variables are square footage, number of bedrooms, and location, and the output variable is the price of the house.
Suppose we have a dataset of 1,000 houses with their respective square footage, number of bedrooms, location, and price. We can use this dataset to train a machine learning model to predict the price of a house based on its features.
The table below shows an example of the dataset:
| Square Footage | No. of Bedrooms | Location | Price |
|---|---|---|---|
| 2,000 | 3 | New York | $500,000 |
| 1,500 | 2 | Chicago | $350,000 |
| 3,000 | 4 | San Francisco | $800,000 |

The machine learning model will learn the relationship between the input variables (square footage, number of bedrooms, and location) and the output variable (price). Once the model is trained, it can be used to predict the price of a new house based on its features.
Unsupervised Learning
Unsupervised learning is a type of machine learning in which the machine is trained on an unlabeled dataset. This means that the dataset only has input variables and no output variables. The machine is given the input variables and it tries to find patterns and relationships in the data without any guidance.
In unsupervised learning, the machine is not given a specific task to perform. Instead, it is left to find patterns and relationships in the data on its own. This type of learning is commonly used in tasks such as clustering, anomaly detection, and dimensionality reduction.
Example of Unsupervised Learning
An example of unsupervised learning is clustering customers based on their shopping behavior. In this case, the input variables are the shopping behavior of customers, and the goal is to group customers with similar shopping behavior together.
Suppose we have a dataset of 1,000 customers and their respective shopping behavior. The table below shows an example of the dataset:
| Cust ID | Amount Spent | Items Purchased | Freq of Purchase |
|---|---|---|---|
| 1 | $100 | 5 | 2 |
| 2 | $50 | 2 | 3 |
| 3 | $200 | 8 | 1 |
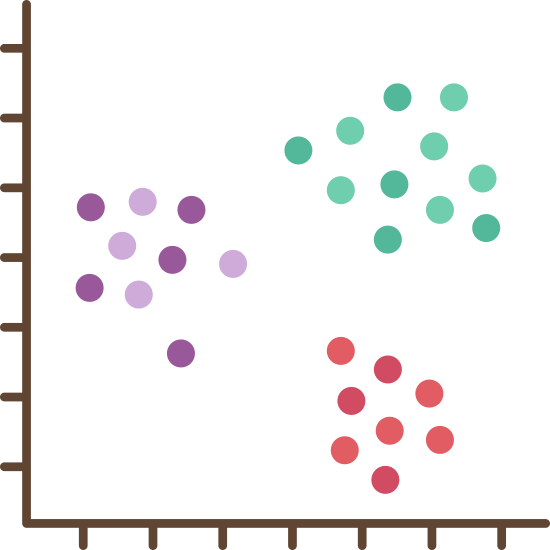
The machine learning model will try to find patterns and relationships in the data and group customers with similar shopping behavior together. Once the model is trained, it can be used to segment customers based on their shopping behavior, which can be useful for targeted marketing campaigns or personalized recommendations.
Key Differences Between Supervised and Unsupervised Learning
| Supervised Learning | Unsupervised Learning |
|---|---|
| Labeled vs. Unlabeled Data | Uses labeled data with input and output variables |
| Task-Oriented vs. Exploration-Oriented | Task-oriented, with a specific task to perform |
| Predictive vs. Descriptive | Predictive, with the goal of predicting an output variable |
| Model Complexity | Models are typically more complex |
References:
- Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: data mining, inference, and prediction. Springer.
- Zhang, K. (2016). An introduction to machine learning. Springer.


